Chi-squared distribution
| Probability density function |
|
| Cumulative distribution function |
|
| Notation | 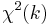 or or 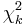 |
|---|---|
| Parameters | k ∈ N1 — degrees of freedom |
| Support | x ∈ [0, +∞) |
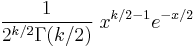 |
|
| CDF | 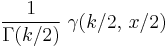 |
| Mean | k |
| Median | 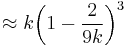 |
| Mode | max{ k − 2, 0 } |
| Variance | 2k |
| Skewness | 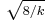 |
| Ex. kurtosis | 12 / k |
| Entropy | 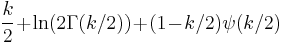 |
| MGF | (1 − 2 t)−k/2 for t < ½ |
| CF | (1 − 2 i t)−k/2 [1] |
In probability theory and statistics, the chi-squared distribution (also chi-square or χ²-distribution) with k degrees of freedom is the distribution of a sum of the squares of k independent standard normal random variables. It is one of the most widely used probability distributions in inferential statistics, e.g., in hypothesis testing or in construction of confidence intervals.[2][3][4][5] When there is a need to contrast it with the noncentral chi-squared distribution, this distribution is sometimes called the central chi-squared distribution.
The chi-squared distribution is used in the common chi-squared tests for goodness of fit of an observed distribution to a theoretical one, the independence of two criteria of classification of qualitative data, and in confidence interval estimation for a population standard deviation of a normal distribution from a sample standard deviation. Many other statistical tests also use this distribution, like Friedman's analysis of variance by ranks.
The chi-squared distribution is a special case of the gamma distribution.
Contents |
Definition
If Z1, ..., Zk are independent, standard normal random variables, then the sum of their squares,
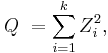
is distributed according to the chi-squared distribution with k degrees of freedom. This is usually denoted as
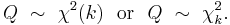
The chi-squared distribution has one parameter: k — a positive integer that specifies the number of degrees of freedom (i.e. the number of Zi’s)
Characteristics
Further properties of the chi-squared distribution can be found in the box at the upper right corner of this article.
Probability density function
The probability density function (pdf) of the chi-squared distribution is
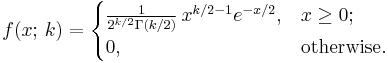
where Γ(k/2) denotes the Gamma function, which has closed-form values at the half-integers.
For derivations of the pdf in the cases of one and two degrees of freedom, see Proofs related to chi-squared distribution.
Cumulative distribution function
Its cumulative distribution function is:
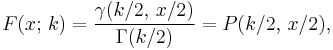
where γ(k,z) is the lower incomplete Gamma function and P(k,z) is the regularized Gamma function.
In a special case of k = 2 this function has a simple form:
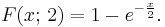
Tables of this distribution — usually in its cumulative form — are widely available and the function is included in many spreadsheets and all statistical packages. For a closed form approximation for the CDF, see under Noncentral chi-squared distribution.
Additivity
It follows from the definition of the chi-squared distribution that the sum of independent chi-squared variables is also chi-squared distributed. Specifically, if {Xi}i=1n are independent chi-squared variables with {ki}i=1n degrees of freedom, respectively, then Y = X1 + ⋯ + Xn is chi-squared distributed with k1 + ⋯ + kn degrees of freedom.
Information entropy
The information entropy is given by
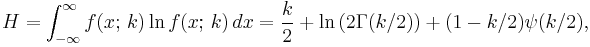
where ψ(x) is the Digamma function.
The Chi-squared distribution is the maximum entropy probability distribution for a random variate X for which 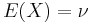 is fixed, and
is fixed, and 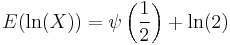 is fixed. [6]
is fixed. [6]
Noncentral moments
The moments about zero of a chi-squared distribution with k degrees of freedom are given by[7][8]
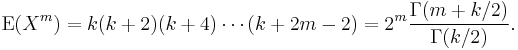
Cumulants
The cumulants are readily obtained by a (formal) power series expansion of the logarithm of the characteristic function:
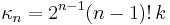
Asymptotic properties
By the central limit theorem, because the chi-squared distribution is the sum of k independent random variables with finite mean and variance, it converges to a normal distribution for large k. For many practical purposes, for k > 50 the distribution is sufficiently close to a normal distribution for the difference to be ignored.[9] Specifically, if X ~ χ²(k), then as k tends to infinity, the distribution of 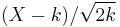 tends to a standard normal distribution. However, convergence is slow as the skewness is
tends to a standard normal distribution. However, convergence is slow as the skewness is 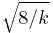 and the excess kurtosis is 12/k. Other functions of the chi-squared distribution converge more rapidly to a normal distribution. Some examples are:
and the excess kurtosis is 12/k. Other functions of the chi-squared distribution converge more rapidly to a normal distribution. Some examples are:
- If X ~ χ²(k) then
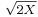 is approximately normally distributed with mean
is approximately normally distributed with mean 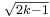 and unit variance (result credited to R. A. Fisher).
and unit variance (result credited to R. A. Fisher). - If X ~ χ²(k) then
![\scriptstyle\sqrt[3]{X/k}](/2012-wikipedia_en_all_nopic_01_2012/I/6bd5442dd615e41c37b9f37030637ce1.png) is approximately normally distributed with mean
is approximately normally distributed with mean 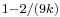 and variance
and variance 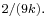 [10] This is known as the Wilson-Hilferty transformation.
[10] This is known as the Wilson-Hilferty transformation.
Related distributions
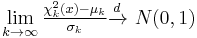 (normal distribution)
(normal distribution)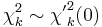 (Noncentral chi-squared distribution with non-centrality parameter
(Noncentral chi-squared distribution with non-centrality parameter 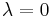 )
)- If
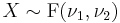 then
then 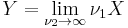 has the chi-squared distribution
has the chi-squared distribution 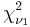
- As a special case, if
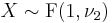 then
then 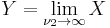 has the chi-squared distribution
has the chi-squared distribution 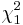
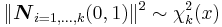 (The squared norm of n standard normally distributed variables is a chi-squared distribution with k degrees of freedom)
(The squared norm of n standard normally distributed variables is a chi-squared distribution with k degrees of freedom)- If
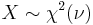 and
and 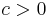 , then
, then 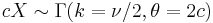 . (gamma distribution)
. (gamma distribution) - If
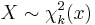 then
then 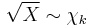 (chi distribution)
(chi distribution) - If
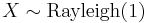 (Rayleigh distribution) then
(Rayleigh distribution) then 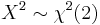
- If
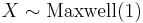 (Maxwell distribution) then
(Maxwell distribution) then 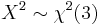
- If
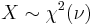 then
then 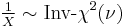 (Inverse-chi-squared distribution)
(Inverse-chi-squared distribution) - The chi-squared distribution is a special case of type 3 Pearson distribution
- If
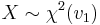 and
and 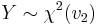 then
then 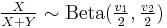 (beta distribution)
(beta distribution) - If
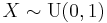 (Uniform distribution (continuous)) then
(Uniform distribution (continuous)) then 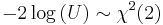
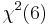 is a transformation of Laplace distribution
is a transformation of Laplace distribution- If
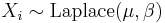 then
then 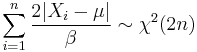
- chi-squared distribution is a transformation of Pareto distribution
- Student's t-distribution is a transformation of chi-squared distribution
- Student's t-distribution can be obtained from chi-squared distribution and normal distribution
- Noncentral beta distribution can be obtained as a transformation of chi-squared distribution and Noncentral chi-squared distribution
- Noncentral t-distribution can be obtained from normal distribution and chi-squared distribution
A chi-squared variable with k degrees of freedom is defined as the sum of the squares of k independent standard normal random variables.
If Y is a k-dimensional Gaussian random vector with mean vector μ and rank k covariance matrix C, then X = (Y−μ)TC−1(Y−μ) is chi-squared distributed with k degrees of freedom.
The sum of squares of statistically independent unit-variance Gaussian variables which do not have mean zero yields a generalization of the chi-squared distribution called the noncentral chi-squared distribution.
If Y is a vector of k i.i.d. standard normal random variables and A is a k×k idempotent matrix with rank k−n then the quadratic form YTAY is chi-squared distributed with k−n degrees of freedom.
The chi-squared distribution is also naturally related to other distributions arising from the Gaussian. In particular,
- Y is F-distributed, Y ~ F(k1,k2) if
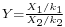 where X1 ~ χ²(k1) and X2 ~ χ²(k2) are statistically independent.
where X1 ~ χ²(k1) and X2 ~ χ²(k2) are statistically independent.
- If X is chi-squared distributed, then
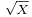 is chi distributed.
is chi distributed.
- If X1 ~ χ2k1 and X2 ~ χ2k2 are statistically independent, then X1 + X2 ~ χ2k1+k2. If X1 and X2 are not independent, then X1 + X2 is not chi-squared distributed.
Generalizations
The chi-squared distribution is obtained as the sum of the squares of k independent, zero-mean, unit-variance Gaussian random variables. Generalizations of this distribution can be obtained by summing the squares of other types of Gaussian random variables. Several such distributions are described below.
Chi-squared distributions
Noncentral chi-squared distribution
The noncentral chi-squared distribution is obtained from the sum of the squares of independent Gaussian random variables having unit variance and nonzero means.
Generalized chi-squared distribution
The generalized chi-squared distribution is obtained from the quadratic form z′Az where z is a zero-mean Gaussian vector having an arbitrary covariance matrix, and A is an arbitrary matrix.
The chi-squared distribution X ~ χ²(k) is a special case of the gamma distribution, in that X ~ Γ(k/2, 2) (using the shape parameterization of the gamma distribution) where k/2 is an integer.
Because the exponential distribution is also a special case of the Gamma distribution, we also have that if X ~ χ²(2), then X ~ Exp(1/2) is an exponential distribution.
The Erlang distribution is also a special case of the Gamma distribution and thus we also have that if X ~ χ²(k) with even k, then X is Erlang distributed with shape parameter k/2 and scale parameter 1/2.
Applications
The chi-squared distribution has numerous applications in inferential statistics, for instance in chi-squared tests and in estimating variances. It enters the problem of estimating the mean of a normally distributed population and the problem of estimating the slope of a regression line via its role in Student’s t-distribution. It enters all analysis of variance problems via its role in the F-distribution, which is the distribution of the ratio of two independent chi-squared random variables, each divided by their respective degrees of freedom.
Following are some of the most common situations in which the chi-squared distribution arises from a Gaussian-distributed sample.
- if X1, ..., Xn are i.i.d. N(μ, σ2) random variables, then
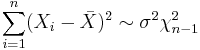 where
where 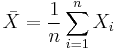 .
.
- The box below shows probability distributions with name starting with chi for some statistics based on Xi ∼ Normal(μi, σ2i), i = 1, ⋯, k, independent random variables:
| Name | Statistic |
|---|---|
| chi-squared distribution | 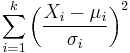 |
| noncentral chi-squared distribution | 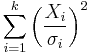 |
| chi distribution | 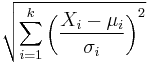 |
| noncentral chi distribution | 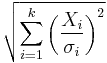 |
Table of χ2 value vs p-value
The p-value is the probability of observing a test statistic at least as extreme in a chi-squared distribution. Accordingly, since the cumulative distribution function (CDF) for the appropriate degrees of freedom (df) gives the probability of having obtained a value less extreme than this point, subtracting the CDF value from 1 gives the p-value. The table below gives a number of p-values matching to χ2 for the first 10 degrees of freedom.
A p-value of 0.05 or less is usually regarded as statistically significant, i.e. the observed deviation from the null hypothesis is significant.
| Degrees of freedom (df) | χ2 value [11] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
1
|
0.004 | 0.02 | 0.06 | 0.15 | 0.46 | 1.07 | 1.64 | 2.71 | 3.84 | 6.64 | 10.83 |
|
2
|
0.10 | 0.21 | 0.45 | 0.71 | 1.39 | 2.41 | 3.22 | 4.60 | 5.99 | 9.21 | 13.82 |
|
3
|
0.35 | 0.58 | 1.01 | 1.42 | 2.37 | 3.66 | 4.64 | 6.25 | 7.82 | 11.34 | 16.27 |
|
4
|
0.71 | 1.06 | 1.65 | 2.20 | 3.36 | 4.88 | 5.99 | 7.78 | 9.49 | 13.28 | 18.47 |
|
5
|
1.14 | 1.61 | 2.34 | 3.00 | 4.35 | 6.06 | 7.29 | 9.24 | 11.07 | 15.09 | 20.52 |
|
6
|
1.63 | 2.20 | 3.07 | 3.83 | 5.35 | 7.23 | 8.56 | 10.64 | 12.59 | 16.81 | 22.46 |
|
7
|
2.17 | 2.83 | 3.82 | 4.67 | 6.35 | 8.38 | 9.80 | 12.02 | 14.07 | 18.48 | 24.32 |
|
8
|
2.73 | 3.49 | 4.59 | 5.53 | 7.34 | 9.52 | 11.03 | 13.36 | 15.51 | 20.09 | 26.12 |
|
9
|
3.32 | 4.17 | 5.38 | 6.39 | 8.34 | 10.66 | 12.24 | 14.68 | 16.92 | 21.67 | 27.88 |
|
10
|
3.94 | 4.86 | 6.18 | 7.27 | 9.34 | 11.78 | 13.44 | 15.99 | 18.31 | 23.21 | 29.59 |
|
P value (Probability)
|
0.95 | 0.90 | 0.80 | 0.70 | 0.50 | 0.30 | 0.20 | 0.10 | 0.05 | 0.01 | 0.001 |
| Nonsignificant | Significant | ||||||||||
See also
- Cochran's theorem
- Fisher's method for combining independent tests of significance
- Generalized chi-squared distribution
- Pearson's chi-squared test
- Wishart distribution
References
- ^ M.A. Sanders. "Characteristic function of the central chi-squared distribution". http://www.planetmathematics.com/CentralChiDistr.pdf. Retrieved 2009-03-06.
- ^ Abramowitz, Milton; Stegun, Irene A., eds. (1965), "Chapter 26", Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, New York: Dover, pp. 940, ISBN 978-0486612720, MR0167642, http://www.math.sfu.ca/~cbm/aands/page_940.htm.
- ^ NIST (2006). Engineering Statistics Handbook - Chi-Squared Distribution
- ^ Jonhson, N.L.; S. Kotz, , N. Balakrishnan (1994). Continuous Univariate Distributions (Second Ed., Vol. 1, Chapter 18). John Willey and Sons. ISBN 0-471-58495-9.
- ^ Mood, Alexander; Franklin A. Graybill, Duane C. Boes (1974). Introduction to the Theory of Statistics (Third Edition, p. 241-246). McGraw-Hill. ISBN 0-07-042864-6.
- ^ Park, Sung Y.; Bera, Anil K. (2009). "Maximum entropy autoregressive conditional heteroskedasticity model". Journal of Econometrics (Elsevier): 219–230. http://www.wise.xmu.edu.cn/Master/Download/..%5C..%5CUploadFiles%5Cpaper-masterdownload%5C2009519932327055475115776.pdf. Retrieved 2011-06-02.
- ^ Chi-squared distribution, from MathWorld, retrieved Feb. 11, 2009
- ^ M. K. Simon, Probability Distributions Involving Gaussian Random Variables, New York: Springer, 2002, eq. (2.35), ISBN 978-0-387-34657-1
- ^ Box, Hunter and Hunter. Statistics for experimenters. Wiley. p. 46.
- ^ Wilson, E.B.; Hilferty, M.M. (1931) "The distribution of chi-squared". Proceedings of the National Academy of Sciences, Washington, 17, 684–688.
- ^ Chi-Squared Test Table B.2. Dr. Jacqueline S. McLaughlin at The Pennsylvania State University. In turn citing: R.A. Fisher and F. Yates, Statistical Tables for Biological Agricultural and Medical Research, 6th ed., Table IV
External links
- Earliest Uses of Some of the Words of Mathematics: entry on Chi squared has a brief history
- Course notes on Chi-Squared Goodness of Fit Testing from Yale University Stats 101 class.
- Mathematica demonstration showing the chi-squared sampling distribution of various statistics, e.g. Σx², for a normal population
- Simple algorithm for approximating cdf and inverse cdf for the chi-squared distribution with a pocket calculator
|
|||||||||||